Scaling the A3C algorithm to multiple machines with Tensorflow.JS

As I have been working on reinforcement learning and it’s application to webcrawlers, I have came across the A3C algorithm. The original A3C approach had it’s flaws and it’s drawbacks when applied to the environment I set up for my needs. This blog post presents a different approach to the A3C algorithm, allowing us to scale it to multiple machines instead of multiple threads, while using Tensorflow.JS on NodeJS for the implementation.
Introduction
For the past months, I have been working on my final project, which I had the chance to realise in the french national institue of research in informatics and automatics (INRIA), among the SPIRALS team. My focus was on using reinforcement learning techniques to allow webcrawlers to adapt automatically to the website they are visiting. I will post a blog article about the subject pretty soon. For this purpose, I got to mess with many of classical reinforcement learning algorithms, before focusing my efforts on deep reinforcement learning.
The A3C algorithm was introduced by the Deepmind team at Google in 2016 : it can be considered a little bit old seeing how fast things are moving in AI, but A3C is still one of the most powerful deep reinforcement learning algorithms to date, and the idea behind it was exactly what I needed for the research project I was working on. It’s original approach however brought some limitations to the environment I set up, so I decided to revisit it in order to fit my needs.
This approach is implemented using Tensorflow.JS under NodeJS, making the problem more challenging and interesting.
The original A3C algorithm
A bit of theory
A3C is short for Asynchronous Advantage Actor-Critic, and behind this long and complicated name, hides a powerful algorithm with simple principles.
I’m assuming the lambda reader have some basic knowledge in reinforcement learning, as I will try to explain the terms used, but this is not sufficient if the global functioning of reinforcement learning is not understood.
We can understand A3C by breaking down it’s name into three part :
- Asynchronous
- Advantage
- Actor-critic
In order to understand the global concept, let’s get into each part in slightly more details.
Actor-critic
Actor-critic methods were brought to us in order to solve a pretty serious problem with Policy Gradient methods : as we were in a Monte Carlo’s situation, we were expected to wait until the end of one episode (one run over our environment), before calculating the reward that the agent obtained. The problem with this approach is that if at some point of the episode, our agent take an action which isn’t optimal, the policy followed will still be averaged as optimal since the good rewards we have piled until now are shadowing the bad one gotten in result of the not optimal action : we want our policy to be optimal, maximizing the reward obtained over time. In mathematical words, the problem with Policy Gradient methods is their high variance, meaning that we tend to take a lot of bad steps, altough the average steps are return a pretty high total reward.
This is where actor-critic comes to help : this method basically bring in a better update function. So, instead of waiting until the end of the episode to update our parametrized policy, we are updating it at each step of our episode :
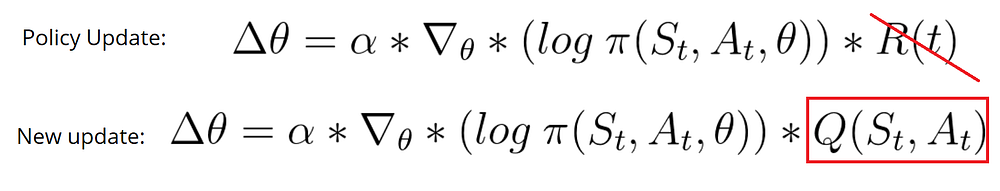
For doing so, we are replacing the total reward R(t) by the action-value (i.e the function calculating the expected maximum future reward given a state and an action taken) for the current state, based on the action that brought the led to it. But how is this action-value function defined ? Well, this is where the magic of actor-critic operates : by using a deep neural network to approximate it.
The first layers of the neural network used generally depends on the use case, but the last layer, the output layer is constituted of an actor, outputing a policy, and a critic, estimating how good (or bad) this policy is expected to be. (We can also use two different networks for the actor and the critic)

As the episodes go, our critic is expected to perform better at estimating how good our policy is supposed to be, and as a consequence, our actor will get better and better at chosing the right policy (or at least, that’s what we hope).
But how are these networks able to learn as the episodes go ?
Neural networks are updated using a process called backpropagation, which basically include the calculation of the loss of the network (i.e the difference between the expected and the returned values), and partially differentiating this loss with respect to the network weights. The update functions used for both the actor and the critic are straightforward. We have seen the policy update, but we yet have to see the value update, used by the critic :

α and β here refer to the learning rate, which is used by the optimizer to update the neural net. γ is the discount factor.
The important parts are highlighted in the yellow boxes : as we can see, the actor loss function can be constructed using the categorical-cross entropy loss, since we can consider one action as one category. The critic update function use what is called the TD (Temporal Difference) error, and so the loss can be constructed by using a simple mean squared error loss. Both losses are then differentiated with respect to the networks weights (Δθ and Δω) and backprop is applied. If more details are needed on how the network weights are updated, please refer to Chris Nicols blog post, everything is explained thoroughly.
So basically, the actor-critic methods use both an actor and a critic represented by a function approximator, which is usually (and in our case) a neural network. It takes the current state St as an input and the actor outputs a policy for that state (i.e an action to take). The critic outputs a value telling how good it is for us to follow this policy at that state. The loss is then computed and the network is updated, so that the next predictions are more accurate.
Asynchronous
If you’ve used Javascript at some point in your life, you may have an idea on what asynchronousity is. For those who haven’t, asynchronousity allows us to perform a (long) action, and rather than wait for it to finish before starting our next task, we let it run and set up a way for it to notify us when it’s done, so we can continue with our next task directly after launching the big long one.
The A3C paper introduces asynchronousity as we are launching multiples agents in parallel, which in their turn, update one global shared neural network. This is the simplified explanation.
Let’s jump a bit deeper here. Take a look to this schematics made by Arthur Juliani in his blog post :
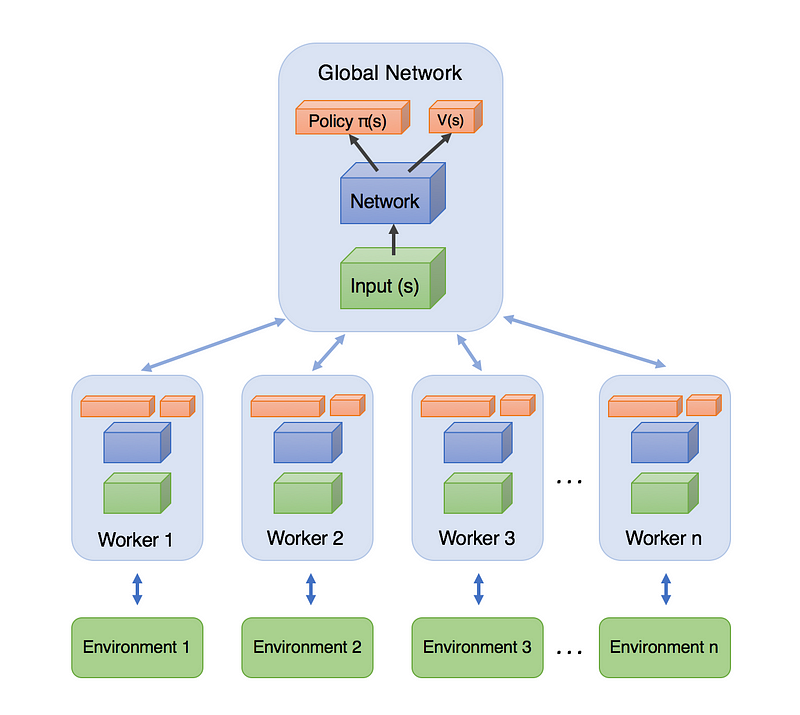
The A3C algorithm brings in this particularity of having different workers, dispatched between disponible threads on the machine, having their own local network used to predict the policy and estimate the value. All the workers are constantly sharing global variables among threads allowing them to keep track of their best score, their average rewards, and the global number of episodes performed.
As one worker gets better than one other, it’s local network weights are transfered to the global network, so basically, the global networks is getting the best possible parameters from all the workers’s local networks.
Not only this allows us to learn faster, but it also allow the workers to constantly share their experience and benefits from the experience of the other workers.
Advantage
Finally, we have seen how the actor-critic methods use the estimate of the action-value to update the policy (and the value). Actor-critic methods solved the problem introduced by Policy Gradient, by allowing us to compute at each step how good the action were.
The A3C algorithm, rather than using the estimate of the action-value, use what we call the advantage, which allows us to compute how much better the action turned out to be than expected so that our network can get a more specific review on what it’s prediction are lacking. (Thanks to A. Juliani again).
The advantage function used by the A3C folks uses the difference between the discounted returns (a discounted form of the total rewards) as an estimate for the action-value, and the value (which is the output of the critic) :

So our policy update function becomes :

Limitations
Now that we have seen globally how the original A3C algorithm works, we can talk about it’s limitations.
In my case, as I was working with webCrawlers, I did not want to have multiple environments executing on the same machine, under the same IP address as this would get websites to notice an increase in traffic coming from my IP, and thus block it temporary, or worse, permanently. So, I wanted to benefit from the advantages of using the A3C algorithm, only, the fact that it was designed to work under multiple threads on the same machine was limitating.
Also, I was trying to get my hands on a ready-to-use implementation on github, but as I was working with NodeJS (my whole environment is written under nodeJs), I was unable to find any implementation of the A3C algorithm. This is why I decided to implement it using Tensorflow.Js.
Scaling A3C to multiple machines
Setting up the communication logic
My approach to scaling the A3C to multiple machines is based on the use of an HTTP communication between a main worker, controlling the global network, and acting as an HTTP server, and multiple secondary workers, working as HTTP clients. The architecture of the system is described in the following schematics :

Let’s describe a little bit this mess and how will the algorithm work. We already know that we must have a movement of networks weights between the global network and the local networks, but this is not all we must share :
- The best score among workers must be shared by all the workers
- We need to set up a FIFO queue containing the best score at each episode (in order to keep a track of our algorithm performances), that the main worker will consume as soon as there is a value in it.
- We also need to keep track of how many workers were launched and when they are all done so the main worker doesn’t run forever.
In the original architecture, these values are saved in global variables. We will use files instead : each worker will send an HTTP POST request to an endpoint whose role is to update a specific file. And if the value is needed for reading rather than updating, we will simply use an HTTP GET request instead.
Here is the list of HTTP endpoints we will be using :
| Endpoint | Request type | Function |
|---|---|---|
| /best_score | GET/POST | Best score among workers |
| /global_episode | GET/POST | Update or read the current number of episode performed by all the workers |
| /global_moving_average | GET/POST | Update the moving average over all workers |
| /worker_done | GET | Remove the worker’s ID from the list of started workers |
| /workers_status | GET | Check if the workers are all done |
| /worker_started | GET | Append the worker’s ID to the started workers list |
| /create_queue | GET | Initiate the global queue |
| /queue | GET/POST | Append or consume a value in the queue |
| /local_model_weights | POST | Transmit local network’s weights onto global network |
| /global_model_weights | GET | For workers to replace their weights with the global model’s |
I am aware that the list could have been shorter but I opted for simplicity. Now that our list of endpoints is set up, we need to implement our HTTP server, using the Express package. Note that we are using the body-parser package in order to parse the requests in JSON format. Also, I have implemented the server to read/write files synchronously, rather than implementing mutex locks (which is an improvement I will be making shortly).
Here is the code for the HTTP endpoints :
const express = require('express');
const app = express();
const fs = require('fs');
const bodyParser = require('body-parser');
app.use(bodyParser.json({limit:'20mb', extended: true}));
app.post('/global_moving_average', (req, res, next) => {
console.log('Updating global moving average');
let avg = req.body.data;
fs.writeFileSync('global_moving_average.txt', avg);
res.send({status: 'SUCCESS'});
});
app.get('/global_moving_average', (req, res, next) => {
console.log('Get global moving average');
let data = fs.readFileSync('global_moving_average.txt', 'utf8');
res.send({status: 'SUCCESS', data: data});
});
app.post('/best_score', (req, res, next) => {
console.log('Updating best_score');
let avg = req.body.data;
fs.writeFileSync('best_score.txt', avg);
res.send({status: 'SUCCESS'});
});
app.get('/best_score', (req, res, next) => {
console.log('Get best_score');
let data = fs.readFileSync('best_score.txt', 'utf8');
res.send({status: 'SUCCESS', data: data});
});
app.get('/create_queue', (req, res, next) => {
fs.closeSync(fs.openSync('queue.txt', 'w'));
res.send({status: 'SUCCESS'});
});
app.post('/queue', (req, res, next) => {
console.log('Adding to queue');
let elem = req.body.data;
console.log('Queue :'+elem);
if(elem !== '')
fs.appendFileSync('queue.txt', elem.toString()+'\n');
res.send({status: 'SUCCESS'});
});
app.get('/queue', (req, res, next) => {
let data = fs.readFileSync('queue.txt', 'utf8').toString().split('\n');
if(data.length === 1 && data[0] === '') {
res.send({status: 'FAIL', data: "NaN", err: 'No data in queue'});
return;
}
let elem_pop = data[0];
let str = '';
for(let i=1;i <data.length;i++) {
if(data[i] != '') str += data[i] + '\n';
}
fs.writeFileSync('queue.txt', str);
res.send({status: 'SUCCESS', data: elem_pop});
});
app.post('/local_model_weights', (req, res, next) => {
console.log('Saving local model into global model...');
let data = req.body.data;
let temporary = req.body.temporary;
if(temporary) {
fs.writeFileSync(__dirname+'/temporary-global-model/weights.bin', data, 'binary');
} else {
fs.writeFileSync(__dirname+'/global-model/weights.bin', data, 'binary');
}
res.send({status: 'SUCCESS'});
});
app.get('/global_model_weights', (req, res, next) => {
console.log('Get global model weights');
res.sendFile(__dirname+'/global-model/weights.bin')
});
app.post('/global_episode', (req, res, next) => {
console.log('Updating global moving average');
let data = parseInt(fs.readFileSync('global_episode.txt', 'utf8'));
data += 1;
fs.writeFileSync('global_episode.txt', data);
res.send({status: 'SUCCESS'});
});
app.get('/global_episode', (req, res, next) => {
console.log('Get global moving average');
let data = fs.readFileSync('global_episode.txt', 'utf8');
res.send({status: 'SUCCESS', data: data});
});
app.get('/worker_done', (req, res, next) => {
console.log('Poping token from workers list');
let data = fs.readFileSync('workers_tokens.txt', 'utf8').toString().split('\n');
if(data.length === 1 && data[0] === '') {
res.send({status: 'FAIL', data: "NaN", err: 'No data in queue'});
}
let elem_pop = data[0];
let str = '';
for(let i=1;i <data.length;i++) {
str += data[i] + '\n';
}
fs.writeFileSync('queue.txt', str);
res.send({status: 'SUCCESS', data: elem_pop});
});
app.get('/workers_status', (res, req, next) => {
console.log('Checking workers status');
let workers = fs.readFileSync('workers_tokens.txt', 'utf8').toString().split('\n');
if(workers.length === 1 && workers[0] === '')
res.send({status: 'SUCCESS', data: 'done'});
else
res.send({status: 'SUCCESS', data: workers.length});
});
app.get('/worker_started', (req, res, next) => {
console.log('Appending token to workers list');
fs.appendFileSync('workers_tokens.txt','1\n');
res.send({status: 'SUCCESS'});
});
const server = app.listen(33333, function() {
let host = server.address().address;
let port = server.address().port;
console.log("Listening on port 33333...");
});
Every POST request should have the content-type header specifying the JSON mediatype, and the data to be updated should be put in a data JSON field. The /local_model_weights endpoint is a bit more complex, as the network’s weights data is parsed into the data JSON field, using a binary encoding. We also specifiy the temporary boolean field, which control wether a the local model’s weights transmited should be effectively applied to the global network (if the worker’s got the best score over the others) or if the weights aren’t optimal over the other worker’s.
Our endpoints are setup (find the full code here), we now need to build the helper functions used by the clients. The implementation is very simple, as we simply perform HTTP requests.
However, the queue is a bit more special as we need the function to be blocking if no data is present in the queue, and to return the value if one is present. Notice that we previously set the HTTP endpoint to send a ‘NaN’ string if no data is present, which will allow us to know wether to stay in a loop or no :
const fs = require('fs');
const http = require('http');
const host = 'localhost'; //whataver your host server is
const port = 33333; //whatever port your server is running on
async function set_global_moving_average(avg) {
const options = {
hostname: host,
port: port,
path: '/global_moving_average',
method: 'POST',
headers: {
'Content-Type': 'application/json'
}
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
resolve(d);
});
});
req.on('error', (error) => {
reject(error);
});
req.write('{"data":'+avg+'}');
req.end();
});
}
async function get_global_moving_average() {
const options = {
hostname: host,
port: port,
path: '/global_moving_average',
method: 'GET'
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
resolve(JSON.parse(d.toString('utf8')).data);
});
});
req.on('error', (error) => {
reject(error);
});
req.end();
});
}
async function get_best_score() {
...
}
async function set_best_score(score) {
...
}
async function send_model(worker_id, temporary) {
const options = {
hostname: host,
port: port,
path: '/local_model_weights',
method: 'POST',
headers: {
'Content-Type': 'application/json'
}
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
resolve(d.toString('utf8'));
});
});
req.on('error', (error) => {
reject(error);
});
let obj = {};
obj.idx = worker_id;
obj.temporary = temporary;
obj.data = fs.readFileSync(__dirname+'/local-model/weights.bin', {encoding: 'binary'});
req.write(JSON.stringify(obj));
req.end();
});
}
async function create_queue() {
const options = {
hostname: host,
port: port,
path: '/create_queue',
method: 'GET',
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
resolve(d.toString('utf8'));
});
});
req.on('error', (error) => {
reject(error);
});
req.end();
});
}
async function write_queue(val) {
const options = {
hostname: host,
port: port,
path: '/queue',
method: 'POST',
headers: {
'Content-Type': 'application/json'
}
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
resolve(d.toString('utf8'));
});
});
req.on('error', (error) => {
reject(error);
});
let obj = {};
obj.data = val;
req.write(JSON.stringify(obj));
req.end();
});
}
async function get_queue() {
const options = {
hostname: host,
port: port,
path: '/queue',
method: 'GET',
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
let data = JSON.parse(d.toString('utf8')).data;
if(data === 'NaN') {
resolve('NaN');
} else {
resolve(parseFloat(data));
}
});
});
req.on('error', (error) => {
reject(error);
});
req.end();
});
}
async function sleep(ms) {
return new Promise(resolve => {
setTimeout(() => {
resolve();
}, ms);
});
}
async function get_blocking_queue() {
let data = 'NaN';
while(data === 'NaN') {
data = await get_queue();
await sleep(750);
}
return Promise.resolve(data);
}
async function start_worker(hostn) {
let host_port = hostn.split(':');
const options = {
hostname: host_port[0],
port: host_port[1],
path: '/start_worker',
method: 'GET',
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
let data = d.toString('utf8');
resolve(data);
});
});
req.on('error', (error) => {
reject(error);
});
req.end();
});
}
async function increment_global_episode() {
...
}
async function notify_worker_done() {
const options = {
hostname: host,
port: port,
path: '/worker_done',
method: 'GET',
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
resolve(d);
});
});
req.on('error', (error) => {
reject(error);
});
req.end();
});
}
async function get_global_model() {
const options = {
hostname: host,
port: port,
path: '/global_model_weights',
method: 'GET',
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
const outStream = fs.createWriteStream(__dirname+'/local-model/weights.bin');
outStream.on('error', reject);
res.pipe(outStream);
res.on('end', () => {
outStream.close();
resolve();
});
});
});
req.on('error', (error) => {
reject(error);
});
req.end();
});
}
async function get_global_episode() {
...
}
async function set_global_episode(ep) {
...
}
async function check_workers() {
const options = {
hostname: host,
port: port,
path: '/worker_status',
method: 'GET',
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
resolve(JSON.parse(d.toString('utf8')).data);
});
});
req.on('error', (error) => {
reject(error);
});
req.end();
});
}
async function wait_for_workers() {
let data = 10000;
while(data !== 0) {
data = await check_workers();
}
return Promise.resolve();
}
async function add_worker_token(tok) {
const options = {
hostname: host,
port: port,
path: '/worker_started',
method: 'GET',
};
return new Promise((resolve, reject) => {
const req = http.request(options, (res) => {
res.on('data', (d) => {
resolve(d);
});
});
req.on('error', (error) => {
reject(error);
});
req.end();
});
}
function get_workers_hostnames() {
let data = fs.readFileSync('workers', 'utf8').toString().split('\n');
return data;
}
...
I voluntarly hid the body of some function that are similar to each others to avoid overloading the code, but you can find the full code here.
The HTTP side is now fully set up, and you can test everything by using an HTTP client and messing with the requests, or even better, by writing unit tests.
Setting up the agent and the main algorithm
Now that the mainstream part is done, we need to setup the network and it’s update rules using tensorflowJs. Make sure to have the tensorflow backend installed and get the @tensorflow/tfjs-node package over npm ( or tfjs-node-gpu if you have CUDA installed).
Now our network architecture will be very simple :

I personally input a onehot encoded tensor of my state, with shape (9, 12) so the network will be based on this input shape. I have around 2000 actions, thus the 2000 policy fully_connected output layer.
The network isn’t very difficul to implement, so let’s get to it :
const tf = require('@tensorflow/tfjs-node-gpu');
class Agent {
constructor(action_size, state_size, num_hidden) {
this.action_size = action_size;
this.state_size = state_size;
this.num_hidden = num_hidden;
this.model = this.build_model();
}
build_model() {
const input = tf.layers.input({shape: [9, 12]}); //oneHot state shape
const fc1 = tf.layers.dense({
units: this.num_hidden,
name: 'dense1',
activation: 'relu',
});
const flatten = tf.layers.flatten(); //Necessary for the dense layer
const policy_output = tf.layers.dense({
units: this.action_size,
name:'policy'
});
const fc2 = tf.layers.dense({
units: this.num_hidden,
name: 'dense2',
activation: 'relu',
});
const value_output = tf.layers.dense({
units: 1,
name: 'value'
});
const output1 = policy_output.apply(flatten.apply(fc1.apply(input)));
const output2 = value_output.apply(flatten.apply(fc2.apply(input)));
const model = tf.model({inputs:input, outputs: [output1, output2]}); //(9, 12) input, ([action_size], [1]) output
model.summary();
return model;
}
call(input) {
const result = this.model.predict(input);
return {'logits': result[0], 'values': result[1]};
}
get_trainable_weights() {
return this.model.getWeights();
}
async reload_weights(path) {
this.model = await tf.loadModel('file://'+path);
return Promise.resolve();
}
}
AND DONE! The network is now fully setup and ready to be trained. Training is usually done by batch of data : we feed the network one certain amount of data (a batch) and get the same amount of outputs, then the update is performed only at the end of the batch.
In order to gather data for our batch, we will set up a Memory object, which we do not need to worry about for now. Just know that it works, as it’s name suggest, as a memory storing our algorithm data :
class Memory{
constructor() {
this.states = [];
this.actions = [];
this.rewards = [];
}
store(state, action, reward) {
this.states.push(state);
this.actions.push(action);
this.rewards.push(reward);
}
clear() {
this.states = [];
this.actions = [];
this.rewards = [];
}
}
Now to the difficult part : how do we compute the loss for the network ? Well, recall the update formulas we saw previously and what I stated : we can use a mean squared loss for the critic, and a categorical cross entropy for the actor.
Value Loss: L = Σ(R - V(s))²
Policy Loss: L = -log(π(s)) * A(s)
Tensorflow.Js is very complete and we can compute the loss pretty easily. Once the loss is computed, we need to calculated the gradient of the loss with respect to the network weights. In Tf.JS, the network weights are variable tensors, so we will use a function caller tf.variableGrads(), which takes a function, in order to compute the gradient with respect to the variables used (which refer only to the network weights). So we finally add one last function to our Agent class :
compute_loss(done, new_state, memory, gamma=0.99) {
const f = () => { let reward_sum = 0.;
// If the episode is over, there is no next state to get the value of.
if(done) {
reward_sum = 0.;
} else {
reward_sum = this.call(tf.oneHot(new_state, 12).reshape([1, 9, 12]))
.values.flatten().get(0);
}
let discounted_rewards = [];
let memory_reward_rev = memory.rewards;
for(let reward of memory_reward_rev.reverse()) { //Discounting rewards (we start from the latest rewards)
reward_sum = reward + gamma * reward_sum;
discounted_rewards.push(reward_sum);
}
discounted_rewards.reverse(); //and we reverse it back to normal (earliest-->latest)
let onehot_states = [];
for(let state of memory.states) {
onehot_states.push(tf.oneHot(state, 12));
}
let init_onehot = onehot_states[0];
for(let i=1; i<onehot_states.length;i++) {
init_onehot = init_onehot.concat(onehot_states[i]); //batch on onehot encoded states
}
let log_val = this.call(
init_onehot.reshape([memory.states.length, 9, 12]) //Input the batch one onehot encoded states
);
let disc_reward_tensor = tf.tensor(discounted_rewards);
let advantage = disc_reward_tensor.reshapeAs(log_val.values).sub(log_val.values);
let value_loss = advantage.square(); //Mean squared error
let policy = tf.softmax(log_val.logits);
let logits_cpy = log_val.logits.clone();
let entropy = policy.mul(logits_cpy.mul(tf.scalar(-1)));
entropy = entropy.sum();
let memory_actions = [];
for(let i=0; i< memory.actions.length; i++) {
memory_actions.push(new Array(this.action_size).fill(0));
memory_actions[i][memory.actions[i]] = 1;
}
memory_actions = tf.tensor(memory_actions);
let policy_loss = tf.losses.softmaxCrossEntropy(memory_actions.reshape([memory.actions.length, this.action_size]), log_val.logits); //computing loss
let value_loss_copy = value_loss.clone();
let entropy_mul = (entropy.mul(tf.scalar(0.01))).mul(tf.scalar(-1));
let total_loss_1 = value_loss_copy.mul(tf.scalar(0.5));
let total_loss_2 = total_loss_1.add(policy_loss);
let total_loss = total_loss_2.add(entropy_mul);
return total_loss.mean().asScalar();
};
return tf.train.adam(1e-4).minimize(f, true, this.get_trainable_weights()) //Updating network
}
Notice that we used the ADAM optimizer with a learning rate of 1e-4. Calling the minimize function automatically perform the gradient computation and optimization, effectively updating the network’s weights.
Okay, our agent is setup, our endpoints are ready and our loss can be computed. All we need to do is setup the worker’s algorithm. Here is how it goes :
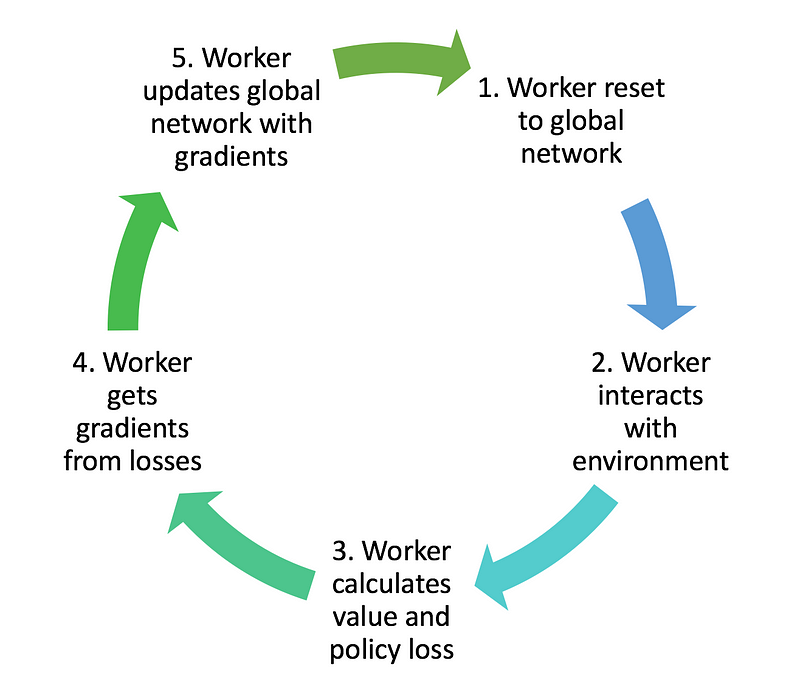
This shouldn’t be difficult to implement as everything else is ready, so let’s jump into it :
...
const worker_utils = require('./worker_utils');
const tf = require('@tensorflow/tfjs-node-gpu');
const math_utils = require('../../utils/math_utils');
async function record(episode, reward, idx, glob_ep_rew, total_loss, num_steps) { //Prints verbose informations and add moving average of episode to queue
let global_ep_reward = glob_ep_rew
if(global_ep_reward == 0) {
global_ep_reward = reward
} else {
global_ep_reward = global_ep_reward * 0.99 + reward*0.01;
}
console.log('Episode :'+episode);
console.log('Moving average reward : '+global_ep_reward);
console.log('Episode reward : '+reward);
console.log('Loss: '+(num_steps == 0 ? total_loss : Math.ceil(total_loss/num_steps*1000)/1000));
console.log("Steps : "+num_steps);
console.log("Worker :"+idx);
console.log('********************* GLOBAL EP REWARD '+global_ep_reward)
await worker_utils.write_queue(global_ep_reward);
return Promise.resolve(global_ep_reward);
}
const environment = require('../environment.js')();
const Agent = require('./agent.js').Agent;
class Worker {
constructor(idx) {
this.worker_idx = idx;
this.ep_loss = 0.0;
this.env = environment.EnvironmentController(1500);
this.update_freq = 10; //Updating the global parameters every 10 episodes
}
async run() { //Analogy to the run function of threads
let total_step = 1;
let mem = new Memory();
await this.env.init_env(true);
let data = this.env.getEnvironmentData();
this.state_size = 9;
this.action_size = data.actions_index.length;
this.agent = new Agent(this.state_size, this.action_size, 24);
for(let i = 0; i < Object.values(data.websites).length; i++) {
let current_state = this.env.reset(i);
mem.clear();
let ep_reward = 0.0;
let ep_steps = 0;
let step_count = 0;
this.ep_loss = 0;
let time_count = 0;
while(true) {
data = this.env.getEnvironmentData(); //The data in my environment are getting updated at every step
console.log('Episode '+i+' : '+(data.current_step+1)+'/'+(data.length_episode+1));
let policy = this.agent.call_actor(tf.oneHot(this.agent.format_state(current_state), 12).reshape([1, 9, 12]));
let action = math_utils.weightedRandomItem( data.actions_index, policy.dataSync());
let step_data = await this.env.step(action);
console.log('-------------');
var next_state = step_data.state,
reward = step_data.reward,
done = step_data.done;
ep_reward += reward;
mem.store(current_state, action, reward);
if(time_count === this.update_freq || done) {
//train local network
let ep_mean_loss = await this.agent.compute_loss(done, mem, next_state);
await worker_utils.send_model(this.worker_idx, true);
this.ep_loss += ep_mean_loss;
console.log(this.ep_loss);
mem.clear();
time_count = 0;
}
if(done) {
let global_epi = await worker_utils.get_global_episode(); //We make our first http call
let old_glob_moving_avg = await worker_utils.get_global_moving_average();
let glob_moving_avg = await record(global_epi, ep_reward, this.worker_idx,
old_glob_moving_avg, this.ep_loss, ep_steps);
await worker_utils.set_global_moving_average(glob_moving_avg);
let global_best_score = await worker_utils.get_best_score();
if( ep_reward > global_best_score) { //Updating global model and reloading the weights
console.log('Updating global model');
await worker_utils.send_model(this.worker_idx, false);
await worker_utils.get_global_model();
await this.agent.reload_weights(__dirname+'/local-model/model.json');
await worker_utils.set_best_score(ep_reward);
}
await worker_utils.increment_global_episode();
break;
}
ep_steps++;
time_count++;
current_state = next_state;
total_step++;
console.log('----------------- END OF TRAINING EPISODE');
}
}
await worker_utils.notify_worker_done();
await worker_utils.write_queue('done'); //Will cause the main worker to stop monitoring
return Promise.resolve();
}
}
const express = require('express');
const app = express();
const bodyParser = require('body-parser');
app.use(bodyParser.json({limit:'10mb', extended: true}));
app.get('/start_worker', (req, res, next) => {
let worker = new Worker(1);
(async() => {
await worker_utils.add_worker_token(1);
await worker.run();
})();
res.send({status: 'SUCCESS'});
});
const argv = require('minimist')(process.argv.slice(2));;
let port = 8085;
if(argv.port || argv.p) port = argv.port ? argv.port : (argv.p ? argv.p : 8085); //Specify port using the -p or --port argument
const server = app.listen(port, function() {
let host = server.address().address;
let port = server.address().port;
console.log("Listening on port "+port+"...");
});
We also set up a new HTTP server in each worker, as it will be listening for the signal to start their job, which the main worker will be sending to each worker. Talking about the main worker, it’s code is very simple : we basically just read the list of available workers, launch them, and keep reading the queue until the workers are done. This way :
...
const environment = require(__dirname+'/../environment')();
const worker_utils = require(__dirname+'/./worker_utils');
const serialiser = require(__dirname+'/../../utils/serialisation');
class MasterAgent {
constructor(n_workers) {
this.amt_workers = n_workers;
}
async init() {
this.name = "SmartbotJs-env";
this.env = environment.EnvironmentController(1500);
await this.env.init_env();
this.env_data = this.env.getEnvironmentData();
this.action_size = this.env_data.actions_index.length;
this.state_size = 9;
console.log(this.state_size, this.action_size);
this.agent = new Agent(this.state_size, this.action_size, 24);
this.agent.model.save('file://global-model/');//We create the folders containing the network parameters
return Promise.resolve();
}
async train() {
worker_utils.create_queue();
let reward_plotting = {};
let workers = worker_utils.get_workers_hostnames();
await (async() => {
const { exec } = require('child_process');
return new Promise((resolve, reject) => {
exec(__dirname+'/init_files.sh', (err, stdout, stderr) => { //Initializing the environment
if(err) reject();
resolve();
});
});
})();
for(let i=0; i<workers.length; i++) { //Sending start HTTP signal to each worker
console.log("Starting worker "+i);
worker_utils.start_worker(workers[i]);
}
let moving_avg_rewards = [];
let i=0;
while(true) {
let reward = await worker_utils.get_blocking_queue();
if(reward !== 'done') {
if(reward !== 'NaN') {
console.log('Pulled new data from queue : '+reward);
moving_avg_rewards.push(parseFloat(reward));
reward_plotting[i] = moving_avg_rewards[i];
await serialiser.serialise({
reward_plotting: reward_plotting,
},'plot_moving_avg_reward_a3c.json'); //This function saves the data in a json filefor a plot later
}
} else {
break;
}
i++;
}
await worker_utils.wait_for_workers(); //Blocking function waiting for workers to pull out their tokens off the list
return Promise.resolve();
}
}
In order to initialise all the files each time the master worker starts, I wrote a simple bash script creating the file and initializing the value inside, which is executed before the algorithm starts :
rm queue.txt global_moving_average.txt best_score.txt global_episode.txt workers_tokens.txt
touch queue.txt global_moving_average.txt best_score.txt global_episode.txt workers_tokens.txt
echo 0 > global_moving_average.txt
echo 0 > global_episode.txt
echo 0 > best_score.txt
And this is it, we’re done !
You can find the full code, along with my environment in my github repository, under the algorithm/a3c folder.
Conclusion
We managed to review the A3C algorithm before using a totally different approach so we can dispatch it over multiple machines. Notice that we can also run multiple envionments on each machines, by specifiying a different port each time, but this will take a toll on your computer’s performances.
I understand that my code isn’t the cleanest nor the best and that mistakes might be involved, along with unclear explications so feel free to comment about any issue that you may encounter.