DuckDB – The little OLAP database that could. TPC-DS Benchmark Results and First Impressions.
Introduction
It’s nearly 2021 and never before have we been so spoiled with the number of different databases used for persisting, retrieval and analysis of all kinds of data. Last time I checked, DB-Engines ranking page listed 359 different commercial and open-source data stores across many different models e.g. relational, key-value, document, time-series etc. It certainly looks like every niche application is accounted for and one may think that there is no or very little room for new players to disrupt this space in a meaningful way. However, on close inspection, it appears that while the majority of use cases have been generously covered for many decades, one quadrant (see image below) has been under-represented. That’s until data science, IoT and edge computing started to become more pervasive and DuckDB was born.
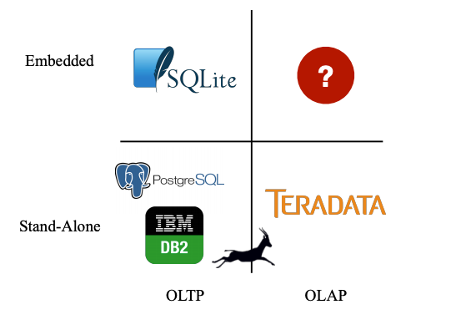
It is no coincidence that demand for edge computing data storage and processing is soaring and many of the big vendors have recognized the unique requirements (and opportunities) this brings to the table e.g. only recently Microsoft announced the release of Azure SQL Edge – a small-footprint, edge-optimized SQL database engine with built-in AI. While Big Data technologies are becoming more pervasive and it’s never been easier to store and process terabytes of data, most business are still grappling with old problems for which throwing distributed cloud computing and storage model is not the panacea. Crunching and analyzing small but complex volumes of data has recently been dominated by Python rich libraries ecosystem, particularly the so-called Python Open Data Science Stack i.e. Pandas, NumPy, SciPy, and Scikit-learn. However, not everyone wants to give up SQL for Python and some of those technologies are not adequate when out-of-memory computation is required. When Hadoop started to gain popularity, many did not want to write Java or Scala jobs, so Cloudera, Hortonworks and other vendors started retrofitting their platforms with SQL interfaces to give end-users the level of abstraction they were comfortable with. This is where DuckDB, still in its infancy (in databases terms), could potentially become another valuable tool, helping analysts and data scientist in harnessing complex data locally with relative ease and speed.
DuckDB is designed to support analytical query workloads, also known as Online analytical processing (OLAP). These workloads are characterized by complex, relatively long-running queries that process significant portions of the stored dataset, for example aggregations over entire tables or joins between several large tables. Changes to the data are expected to be rather large-scale as well, with several rows being appended, or large portions of tables being changed or added at the same time.
To efficiently support this workload, it is critical to reduce the amount of CPU cycles that are expended per individual value. The state of the art in data management to achieve this are either vectorized or just-in-time query execution engines. DuckDB contains a columnar-vectorized query execution engine, where queries are still interpreted, but a large batch of values from a single (a ‘vector’) are processed in one operation. This greatly reduces overhead present in traditional systems such as PostgreSQL, MySQL or SQLite which process each row sequentially. Vectorized query execution leads to far better performance in OLAP queries.
Just like SQLite, DuckDB has no external dependencies, neither for compilation nor during run-time. For releases, the entire source tree of DuckDB is compiled into two files, a header and an implementation file, a so-called ‘amalgamation’. This greatly simplifies deployment and integration in other build processes. For building, all that is required to build DuckDB is a working C++11 compiler.
For DuckDB, there is no DBMS server software to install, update and maintain. DuckDB does not run as a separate process, but completely embedded within a host process. For the analytical use cases that DuckDB targets, this has the additional advantage of high-speed data transfer to and from the database. In some cases, DuckDB can process foreign data without copying. For example, the DuckDB Python package can run queries directly on Pandas data without ever importing or copying any data.
As far as I can tell, there is nothing like this on the market at the moment and DuckDB has found its unique niche i.e. dependency-free, embedded datastore for processing OLAP-style, relational data with speed and ease.

Also, if you’re interested in what motivated the founders of DuckDB to create it and a high-level system overview, there is a really good talk published by the CMU Database Group on YouTube (see video below).
Performance Analysis
If you follow database trends, ClickHouse is emerging as the go-to, open-source darling of on-prem and cloud OLAP-style data processing engine. I’m yet to get my hands on it and take it for a spin but I feel it would be unfair to compare it to DuckDB as they are intended for different crowd and applications. Both are open-source, column-oriented, OLAP databases but while Clickhouse is targeting distributed, enterprise-grade, big data workloads, DuckDB was developed primarely to bridge the gap between locally deployed databases and data science, dealing with small-to-medium data volumes. As such, in this post I will not compare individual RDBMSs and only outline how to load TPC-DS benchmark data and run SQL queries to look at DuckDB analytical workload performance.
Firstly, let’s load some data. Flat files with test data were staged on a PCI-E SSD drive and all subsequent operations and queries were run on a Mac Pro 2012 with 112GB of memory and 2 x Intel Xeon X5690 CPUs. The following script creates an empty DuckDB database and schema. It also loads 10GB TPC-DS data, spread across 25 CSV files, using COPY command (for performance testing I also repeated this process for 20GB and 30GB data sets).
import duckdb
import sys
import os
from pathlib import PurePosixPath, Path
from timeit import default_timer as timer
from humanfriendly import format_timespan
sql_schema = PurePosixPath("/Path/Code/SQL/tpcds_ddls.sql")
tpc_ds_files_raw = r"/Path/Data/10GB/"
duckdb_location = PurePosixPath("/Path/DB/")
duckdb_filename = "testdb.db"
csv_file_delimiter = '|'
def get_sql(sql_schema):
table_name = []
query_sql = []
with open(sql_schema, "r") as f:
for i in f:
if i.startswith("----"):
i = i.replace("----", "")
table_name.append(i.rstrip("\n"))
temp_query_sql = []
with open(sql_schema, "r") as f:
for i in f:
temp_query_sql.append(i)
l = [i for i, s in enumerate(temp_query_sql) if "----" in s]
l.append((len(temp_query_sql)))
for first, second in zip(l, l[1:]):
query_sql.append("".join(temp_query_sql[first:second]))
sql = dict(zip(table_name, query_sql))
return sql
def BuildSchema(conn, tables, csv_file_delimiter, duckdb_location, duckdb_filename, sql, tpc_ds_files_raw):
sql = {x: sql[x] for x in sql if x in tables}
for k, v in sql.items():
try:
cursor = conn.cursor()
cursor.execute(v)
copysql = "COPY {table} FROM '{path}{table}.csv' (DELIMITER '{delimiter}')".format(
table=k, path=tpc_ds_files_raw, delimiter=csv_file_delimiter)
print('Loading table {table} into {dbname} database...'.format(dbname=duckdb_filename,
table=k), end="", flush=True)
table_load_start_time = timer()
cursor.execute(copysql)
table_load_end_time = timer()
table_load_duration = table_load_end_time - table_load_start_time
file_row_rounts = sum(
1
for line in open(
tpc_ds_files_raw+k+'.csv',
newline="",
)
)
cursor.execute(
"SELECT COUNT(1) FROM {table}".format(
table=k)
)
record = cursor.fetchone()
db_row_counts = record[0]
if file_row_rounts != db_row_counts:
raise Exception(
"Table {table} failed to load correctly as record counts do not match: flat file: {ff_ct} vs database: {db_ct}.\
Please troubleshoot!".format(
table=k,
ff_ct=file_row_rounts,
db_ct=db_row_counts,
)
)
else:
print('{records} records loaded successfully in {time}.'.format(
records=db_row_counts, time=format_timespan(table_load_duration)))
cursor.close()
except Exception as e:
print(e)
sys.exit(1)
if __name__ == "__main__":
if os.path.isfile(os.path.join(duckdb_location, duckdb_filename)):
os.remove(os.path.join(duckdb_location, duckdb_filename))
conn = duckdb.connect(os.path.join(duckdb_location, duckdb_filename))
ver = conn.execute("PRAGMA version;").fetchone()
print('DuckDB version (git short hash) =', ver[1])
sql_schema = get_sql(sql_schema)
tables = [q for q in sql_schema]
BuildSchema(conn, tables, csv_file_delimiter, duckdb_location,
duckdb_filename, sql_schema, tpc_ds_files_raw)
conn.close()
Looking at the execution times, the script run in just over 20 minutes. Largest table (size-wise), i.e. ‘store_sales’, containing over 28 million records took just under 3 minutes, whereas a table with the highest amount of records i.e. ‘inventory’ took over 11 minutes.
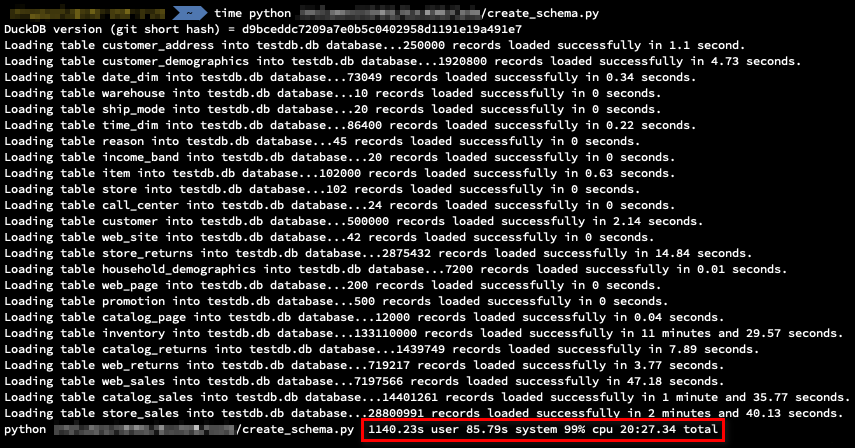
These are not bad times, however, given that each one of the COPY statements was associate with the same database connection, on load completion all data was stored in the write-ahead log (WAL) file, as opposed to the database file. This creates a significant problem as check-pointing the WAL file does no occur until a new connection is instantiated. As such, any subsequent operation is bound to take a long time, waiting for WAL check-pointing as described in the following issue.
If I chose to initiate a new connection for each file loaded, the load time exploded to over 1 hour, most of it spent waiting for WAL file to transfer all the appended transactions into the database file. As DuckDB does not currently offer application-initiated WAL checkpointing and automated WAL truncation does not rely on the number of pages written or connection closing, I feel this may be a difficult teething issue to get around when using DuckDB for more production-grade applications.
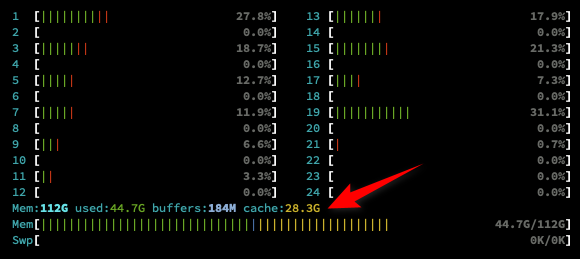
Another problem is memory usage. When loading 10GB of data, overall system memory usage exceed 40GB (quarter of it used by the system itself). Granted I had over 100GB of RAM available for testing on the target machine, this was not a problem, however, it seems to me that the issues many data scientist face when using Pandas for data analysis related to excessive memory usage may not be elevated with this tool. Below is a screenshot of some of the system stats with data temporarily paged in memory before being serialized for loading into the WAL file.
With data loaded into the target database, I scraped all of TPC-DS queries off the DuckDB website (link HERE) and run those across 10GB, 20GB and 30GB datasets to see how a typical OLAP-style analysis will perform. DuckDB TPC-DS benchmark coverage does not include queries 68, 76 and 89 but the tool is capable of executing all other SQL statements without any adjustments or modifications.
import duckdb
import sys
import os
import pandas as pd
from pathlib import PurePosixPath, Path
from timeit import default_timer as timer
from humanfriendly import format_timespan
sql_queries = PurePosixPath("/Path/Code/SQL/tpcds_sql_queries.sql")
execution_results = PurePosixPath("/Path/results.xlsx")
duckdb_location = PurePosixPath("/Path/DB/")
duckdb_filename = "testdb.db"
queries_skipped = ['Query68', 'Query76', 'Query89']
execution_rounds = 3
def get_sql(sql_queries):
query_number = []
query_sql = []
with open(sql_queries, "r") as f:
for i in f:
if i.startswith("----"):
i = i.replace("----", "")
query_number.append(i.rstrip("\n"))
temp_query_sql = []
with open(sql_queries, "r") as f:
for i in f:
temp_query_sql.append(i)
l = [i for i, s in enumerate(temp_query_sql) if "----" in s]
l.append((len(temp_query_sql)))
for first, second in zip(l, l[1:]):
query_sql.append("".join(temp_query_sql[first:second]))
sql = dict(zip(query_number, query_sql))
return sql
def run_sql(
query_sql, query_number, conn
):
try:
cursor = conn.cursor()
query_start_time = timer()
rows = cursor.execute(query_sql)
query_end_time = timer()
rows_count = sum(1 for row in rows)
query_duration = query_end_time - query_start_time
print(
"Query {q_number} executed in {time}...{ct} rows returned.".format(
q_number=query_number,
time=format_timespan(query_duration),
ct=rows_count,
)
)
except Exception as e:
print(e)
finally:
cursor.close()
def time_sql(index_count, pd_index, exec_round, conn, sql, duckdb_location, duckdb_filename):
exec_results = {}
for key, val in sql.items():
query_sql = val
query_number = key.replace("Query", "")
try:
cursor = conn.cursor()
query_start_time = timer()
cursor.execute(query_sql)
records = cursor.fetchall()
query_end_time = timer()
rows_count = sum(1 for row in records)
query_duration = query_end_time - query_start_time
exec_results.update({key: query_duration})
print(
"Query {q_number} executed in {time}...{ct} rows returned.".format(
q_number=query_number,
time=format_timespan(query_duration),
ct=rows_count,
)
)
cursor.close()
except Exception as e:
print(e)
df = pd.DataFrame(list(exec_results.items()), index=pd_index, columns=[
"Query_Number", "Execution_Time_"+str(exec_round)])
return(df)
def main(sql, duckdb_location, duckdb_filename):
index_count = len(sql.keys())
pd_index = range(0, index_count)
dfs = pd.DataFrame()
for exec_round in range(1, execution_rounds+1):
print('\nRunning Execution Round {r}'.format(r=exec_round))
conn = duckdb.connect(os.path.join(duckdb_location, duckdb_filename))
df = time_sql(index_count, pd_index, exec_round, conn,
sql, duckdb_location, duckdb_filename)
dfs = pd.concat([dfs, df], axis=1, sort=False)
dfs = dfs.loc[:, ~dfs.columns.duplicated()]
conn.close()
dfs['Mean_Execution_Time'] = round(dfs.mean(axis=1),2)
dfs.to_excel(execution_results,
sheet_name='TPC-DS_Exec_Times', index=False)
if __name__ == "__main__":
sql = get_sql(sql_queries)
if queries_skipped:
sql = {k: v for k, v in sql.items() if k not in queries_skipped}
main(sql, duckdb_location, duckdb_filename)
Each set of queries was run 3 times and final execution time calculated as the mean of those 3 iterations. The following table (click on image to enlarge) represents queries processing time for TPC-DS scaling factor 10, 20 and 30.
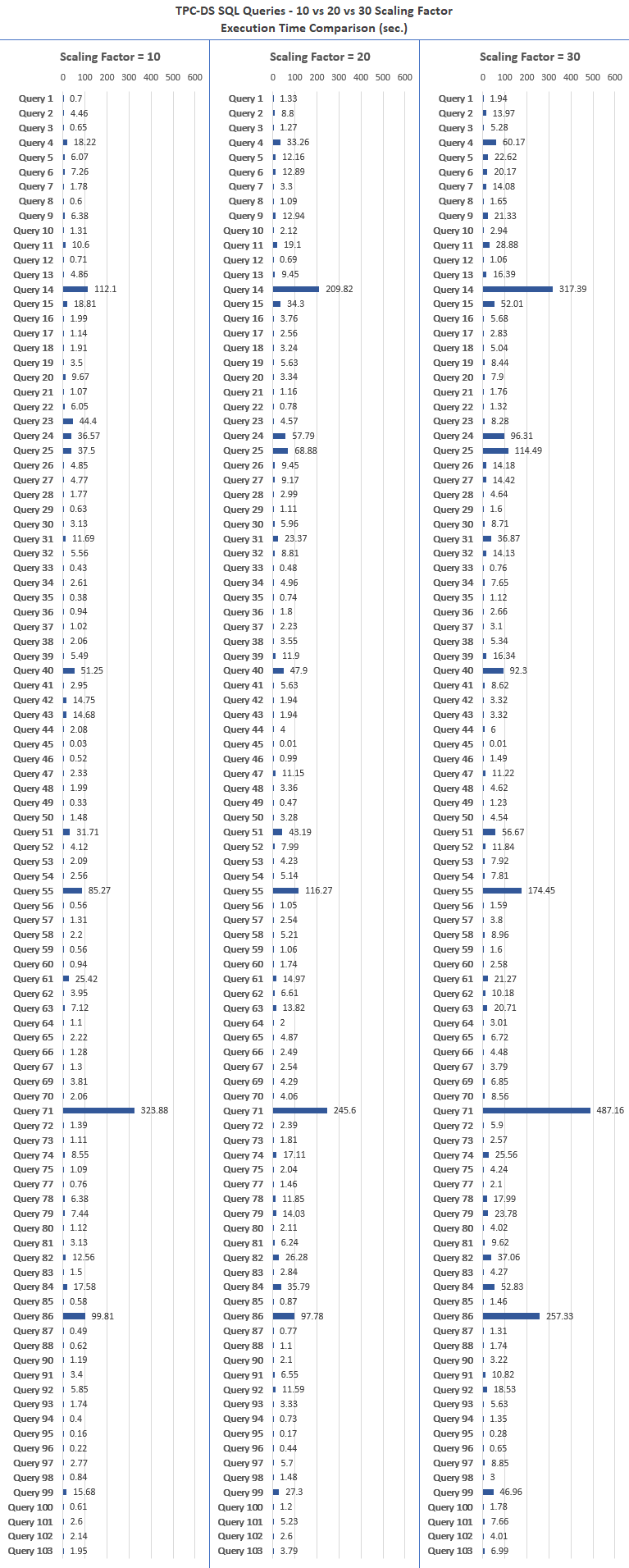
Looking at the results, most queries scale fairly linearly. Outside of a few exceptions, data processing time doubled every time its volume was doubled. There were a few outliers e.g. strangely Query 71 took longer when run against 10GB data set than when executed against 20GB size, however, for the most part it seems that the relationship between data size and query execution time is correlated.
Given that many of those queries are rather complex, I think that DuckDB performance was very good and that its columnar-vectorized query execution engine was up to the task. DuckDB claims that its vectorized query engine is superior to that of traditional RDBMS systems which crunch data tuple-at-a-time e.g. SQLite, MySQL or column-at-a-time e.g. Pandas due to the fact it’s optimized for CPU cache locality i.e. storing data in L1 and L2 cache, with very low latency. Based on the times recorded, I tend to agree and even though I have not run a comparison benchmark on other database engines, for an in-process (no server), single-file storage, no-dependencies software, I reckon DuckDB could outperform many commercial RDBMS systems on a similar hardware and volume of data in an OLAP-style scenarios.
Conclusion
From the short time I spent with DuckDB, I really like the idea of having a single-file, small and compact database at my disposal. Having the option to load text data into a SQLite-like database with relative ease and run analytics using plain, old vanilla SQL is both refreshing and practical. Whilst most times I would be inclined to use an established client-server RDBMS for all my data needs, DuckDB seems like it can comfortably occupy the unexplored niche – fast OLAP data storage and processing engine that one can use without worrying about complex deployment, set-up, configuration and tuning. It’s like a hummingbird of databases – small and fast – and while not (yet) as mature and full-featured as some of the stalwarts of the industry, it carries a lot of potential for workloads it’s designated to be used against.
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Sunday, November 1st, 2020 at 3:02 pm and is filed under Programming, SQL. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



admin December 27th, 2020 at 11:07 am
Hi Leo
I can’t really answer your question without fully understanding your requirements…sorry. I suggest you run a little POC to see if it fits the bill and whether the migration/transition would be a worthwhile investment.
You also said you have a data warehouse but it’s tightly controlled by IT. Rather than trying to run a shadow IT and introduce new tools and frameworks into the mix I would try to convince the DW owner to let you utilize it instead (providing it stores data you require). After all, enterprise DW is there to give you a single, 360 degree view of all the business activities and it’s very common for DS/BI teams to tap directly into it. Nothing wrong with solving ‘the last mile’ problem with desktop FOSS tools but if you need to crunch a lot of data that’s already stored in the DW, at best you may find yourself duplicating the work someone else has already done or at worst, you may be going against the company’s enterprise architecture or security guidelines. However, if your company has more relaxed data governance stance, I suggest you get an extract of the data you’re trying analyze in something like a parquet file (maybe de-identify or anonymize it if required) or and throw it into DuckDB – after all, that’s what this tool is designed for.
SQLite and DW are two very different beasts, typically used for two different scenarios. DuckDB would possibly be a great fit for OLAP-style, small to medium data (you already mentioned you don’t have a lot of it) so your use case may suit what it was designed for. However, make sure you test it first and evaluate it on your own merits – I can’t stress this enough.